
Text Mining with Python Part 3: Transforming Your Tokens
This how you convert your tokens into a data table for analysis.

Are you new to this tutorial series? Check out Part 1 here.
Part 2 of this series taught you how to build a robust text pre-processing pipeline. This pipeline performs the following steps:
Case folding
Tokenization
Removing punctuation
Stopword removal
Generating n-grams
While text pre-processing is a necessary step, it’s not enough on its own for analyzing free-form text. Here’s why.
Every battle-tested analytics technique commonly used with business data has a simple requirement:
Your data needs to be in a table.
And that includes the tokens produced by your text pre-processing pipeline.
This week’s tutorial will teach you how to transform your tokens into a data table using the bag-of-words model. As always, it’s highly recommended that you follow along by writing and running the code that you see in this tutorial.
FYI - While I’m using Python in Excel for this tutorial series, the code is 99+% the same whether you’re using Microsoft Excel or a technology like Jupyter Notebook.
Transforming a Document into Rows of Data
The first step in transforming your tokens is deciding how to map tokens from the documents in your collection (i.e., your corpus) to a table.
It’s most common in text mining to choose the following mapping:
Documents are the rows of the table
Tokens are the columns of the table.
There are a couple of details about this mapping I should mention.
First, the columns are built from the vocabulary of your corpus, where the vocabulary is the collection of unique tokens across all documents in the corpus.
For example, let’s say the token customer appears in many documents in your corpus. The vocabulary would have a single entry for customer, not multiple entries.
Second, because the columns of the table are the vocabulary of your corpus, the columns are usually referred to as the terms.
This tabular structure, where documents are rows and terms are columns, is commonly referred to as a document-term matrix. You can think of a matrix as being synonymous with a table.
Document Vectors Are the Rows
The most common way to represent documents in text mining is using vectors. While there are formal definitions of a vector, all you need is a practical understanding:
A document vector is a collection of numeric values that represent the content of the document.
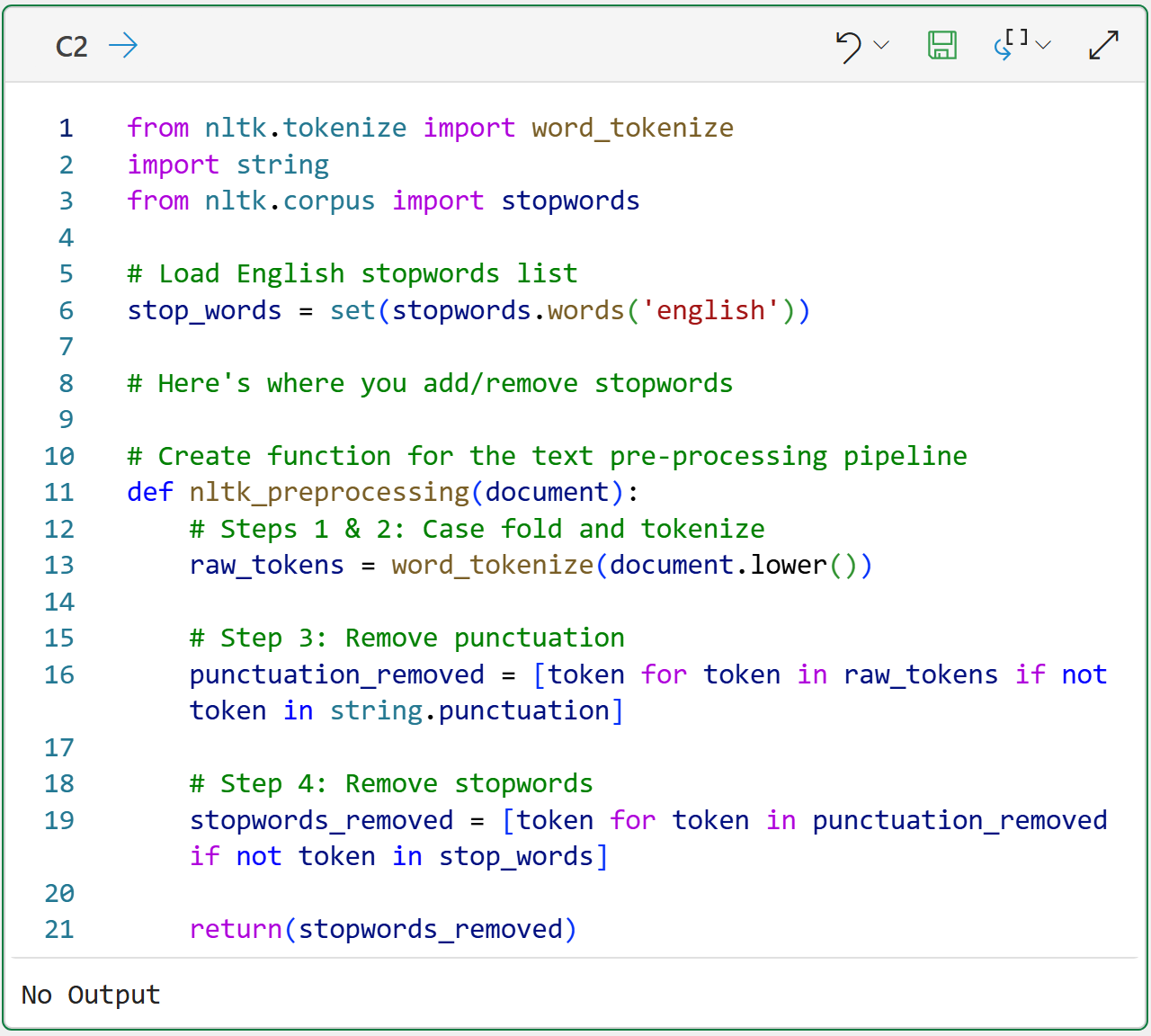
In order to transform the documents in a reproducible way, creating a function for a text pre-processing pipeline is a good idea:
And the code for your Excel workbook:
from nltk.tokenize import word_tokenize
import string
from nltk.corpus import stopwords
# Load English stopwords list
stop_words = set(stopwords.words('english'))
# Here's where you add/remove stopwords
# Create function for the text pre-processing pipeline
def nltk_preprocessing(document):
# Steps 1 & 2: Case fold and tokenize
raw_tokens = word_tokenize(document.lower())
# Step 3: Remove punctuation
punctuation_removed = [token for token in raw_tokens if not token in string.punctuation]
# Step 4: Remove stopwords
stopwords_removed = [token for token in punctuation_removed if not token in stop_words]
return(stopwords_removed)If you’re new to Python, my Python in Excel Accelerator online course will teach you the fundamentals you need for analytics in a weekend.
The code above is super handy and easy to copy and paste across your workbooks for future text mining.
With the pre-processing in place, consider the following:
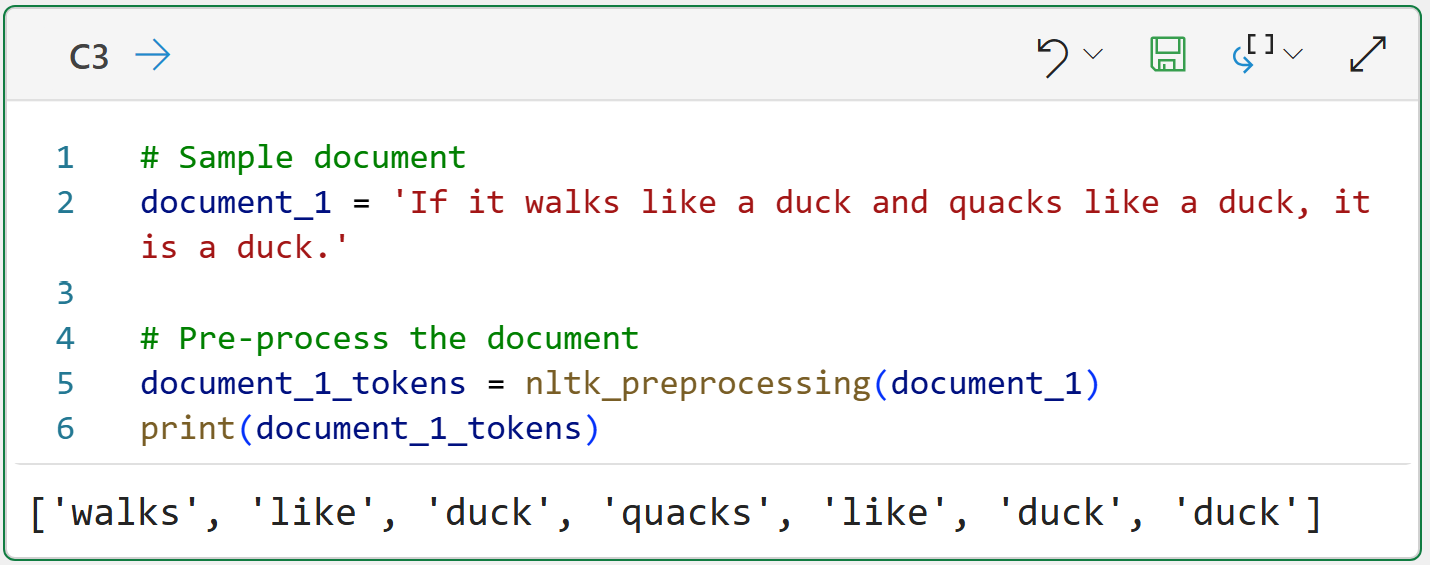
# Sample document
document_1 = 'If it walks like a duck and quacks like a duck, it is a duck.'
# Pre-process the document
document_1_tokens = nltk_preprocessing(document_1)
print(document_1_tokens)The code above pre-processes the document and returns a list of tokens.
However, this isn’t a document vector because it isn’t a numeric representation of the document’s contents. So, the list of tokens needs to be transformed into the count of the tokens in the document:
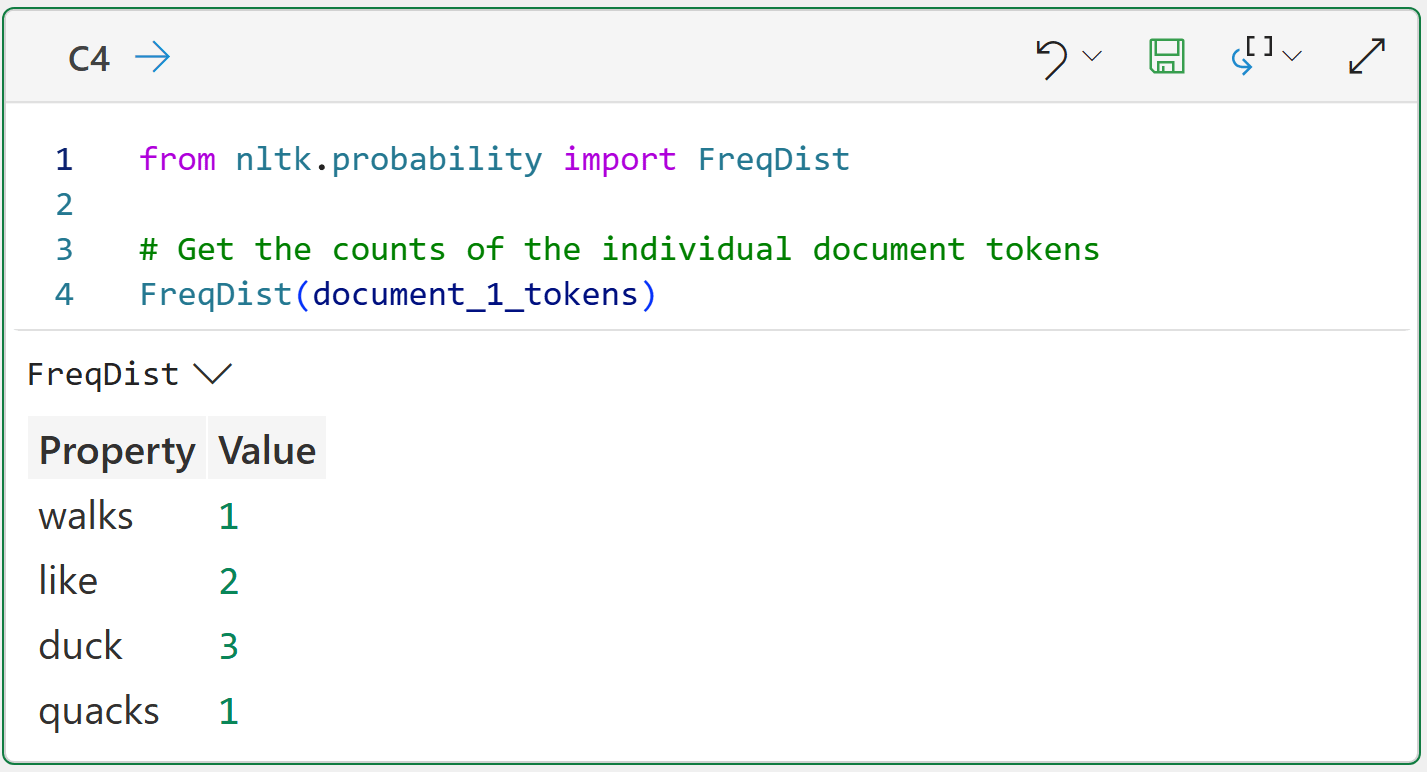
from nltk.probability import FreqDist
# Get the counts of the individual document tokens
FreqDist(document_1_tokens)Take a look at the output of the Python formula in cell C4. Calculating the counts of the individual tokens accomplishes two things:
It gives you the vocabulary of the document (i.e., the unique tokens).
It gives you a numeric representation of the contents of the documents (i.e., vector).
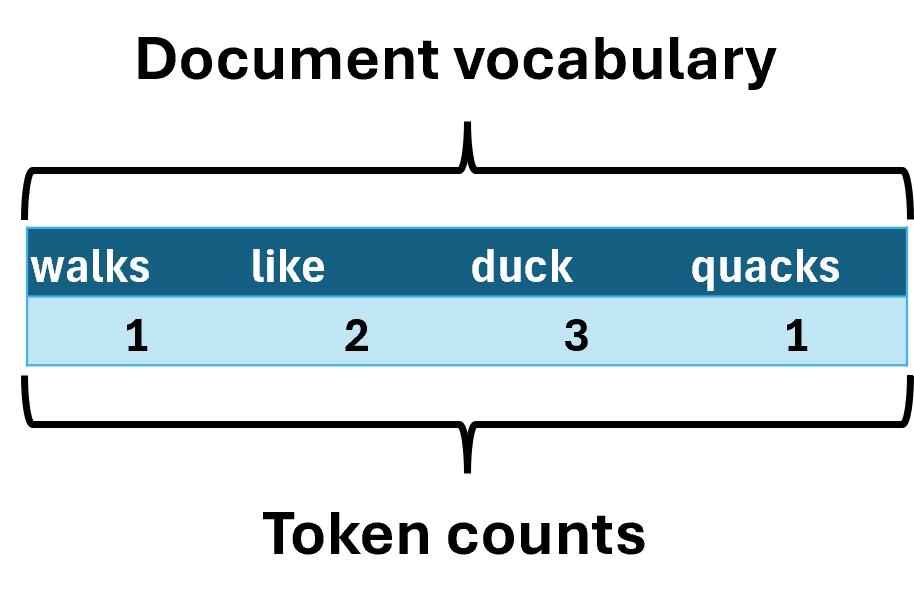
Pivoting the data makes this a lot clearer:
Transforming a Document Corpus
Using a single document to build an understanding of text mining concepts is very useful. However, in the real world, your text mining will use document collections.
The following demonstrates tokenizing the simplest scenario of a corpus of two documents:
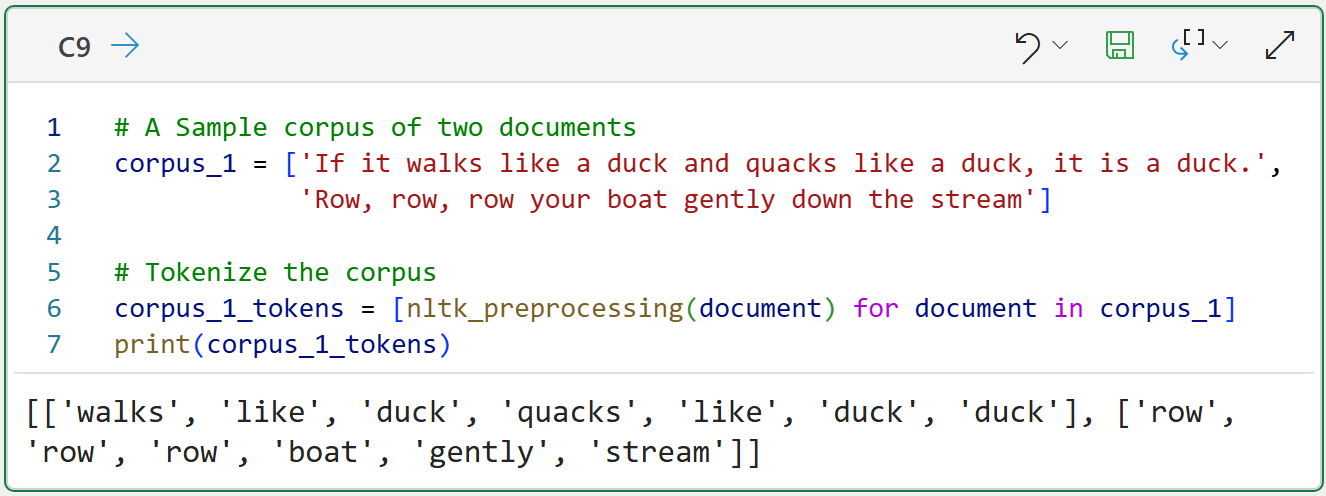
# A Sample corpus of two documents
corpus_1 = ['If it walks like a duck and quacks like a duck, it is a duck.',
'Row, row, row your boat gently down the stream']
# Tokenize the corpus
corpus_1_tokens = [nltk_preprocessing(document) for document in corpus_1]
print(corpus_1_tokens)The Python formula in cell C9 shows that corpus tokenization simply tokenizes each document and stores the results collectively. In this case, a list of lists.
When tokenizing a corpus to create a document-term matrix, the vocabulary expands to include all unique tokens across all documents.
The following image demonstrates the bag-of-words model for the above corpus:

The image above demonstrates a common theme in text mining.
As the number and length of the documents in the corpus grow, you tend to see an explosion in the size of the document-term matrix vocabulary.
It’s common in real-world text mining for a document-term matrix to have 10,000, 100,000, or even more terms in its vocabulary.
The image above also illustrates another theme in text mining.
As the vocabulary of the document-term matrix grows, most of the cells in the table don’t contain any information (i.e., most of the cells are zero).
This is a sparse matrix: the table is large but contains relatively little information because most cells are empty.
So, how do you create these sparse document-term matrices?
Enter the mighty scikit-learn library.
Building Document-Term Matrices with scikit-learn
Python’s scikit-learn library provides a number of useful classes and functions for text mining.
One of the most important of these classes is the CountVectorizer for creating document-term matrices:
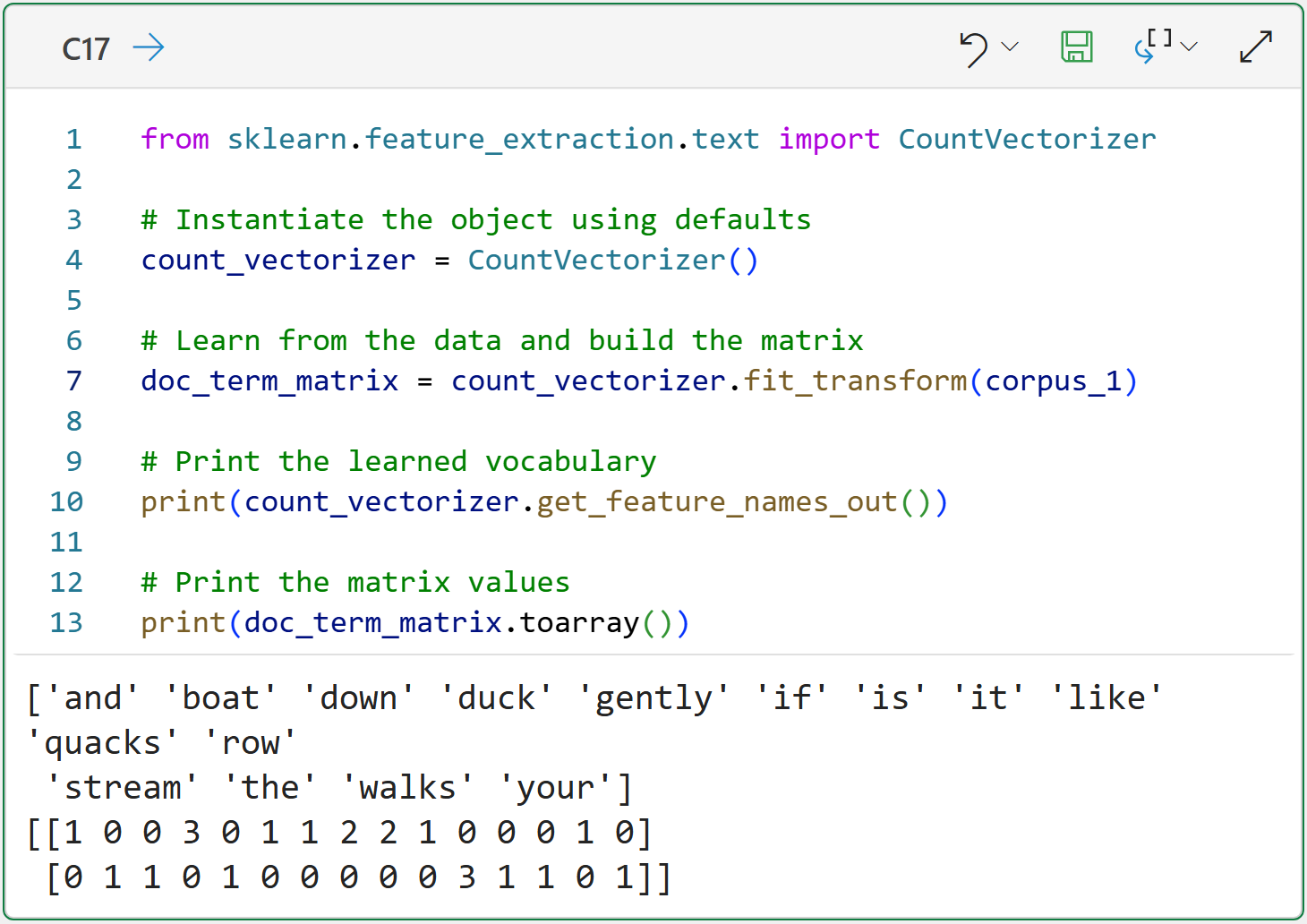
from sklearn.feature_extraction.text import CountVectorizer
# Instantiate the object using defaults
count_vectorizer = CountVectorizer()
# Learn from the data and build the matrix
doc_term_matrix = count_vectorizer.fit_transform(corpus_1)
# Print the learned vocabulary
print(count_vectorizer.get_feature_names_out())
# Print the matrix values
print(doc_term_matrix.toarray())Take a look at the Python formula output for cell C17 because it demonstrates some of the default features of the CountVectorizer class:
Documents are case-folded.
Documents are tokenized.
Punctuation is removed.
Stopwords are not removed.
The vocabulary is in alphabetical order (i.e., it’s a bag of words).
While this default behavior is helpful, the Natural Language Toolkit (NLTK) provides more robust support for text preprocessing.
Fortunately, the CountVectorizer supports using a custom tokenizer function:
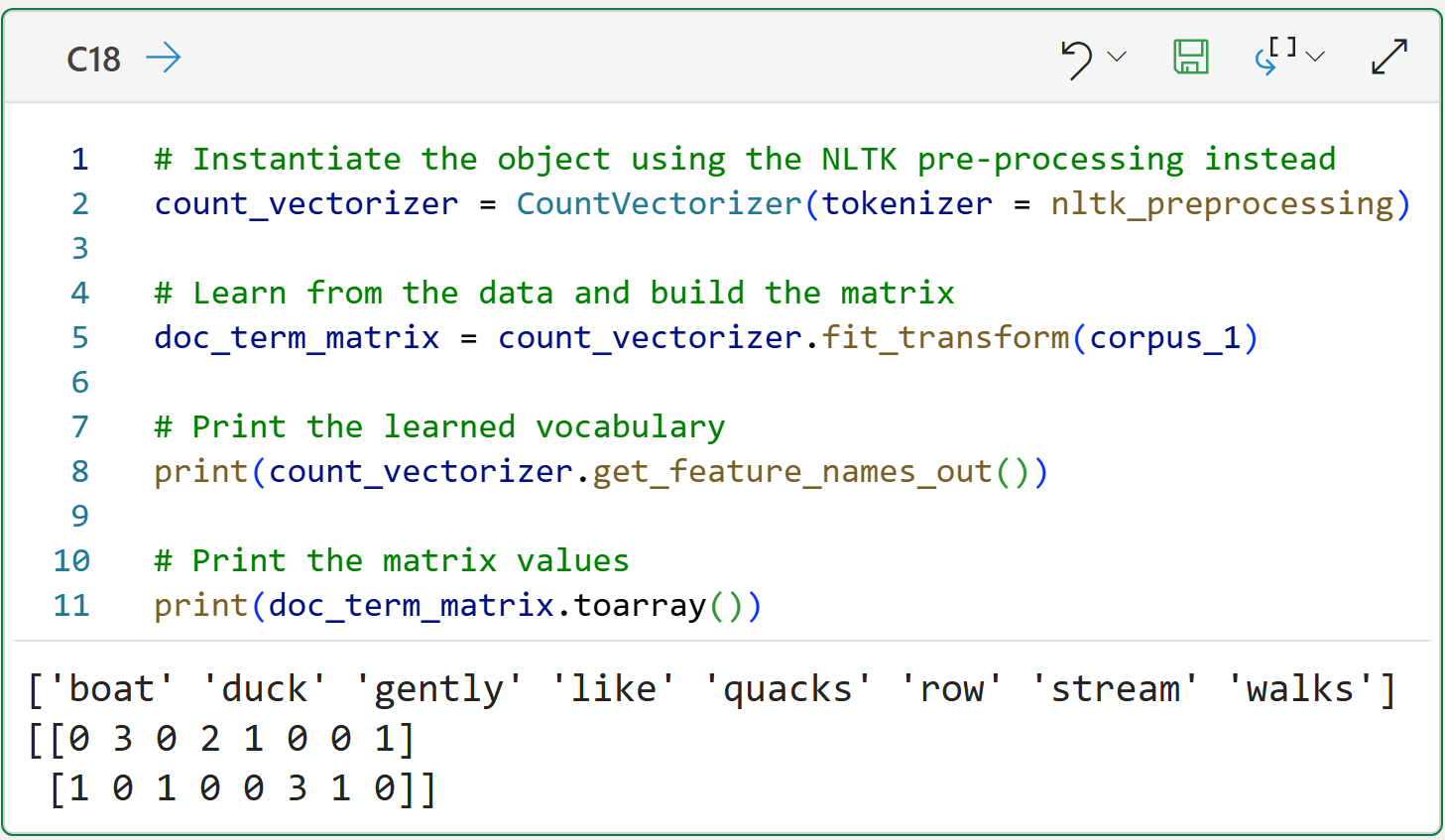
# Instantiate the object using the NLTK pre-processing instead
count_vectorizer = CountVectorizer(tokenizer = nltk_preprocessing)
# Learn from the data and build the matrix
doc_term_matrix = count_vectorizer.fit_transform(corpus_1)
# Print the learned vocabulary
print(count_vectorizer.get_feature_names_out())
# Print the matrix values
print(doc_term_matrix.toarray())The above Python formula demonstrates that the NTLK and scikit-learn are like chocolate and peanut butter - better together.
That’s it for this tutorial.
My next tutorial in this series will cover working with a real-world dataset, including visualizing the results using word clouds.
Stay healthy and happy data sleuthing!
👩🏫 Ready to Learn More Analytics Skills?
My paid subscribers have access to exclusive monthly live crash courses that include:
PDFs of all slides.
Excel workbooks, code, and data.
Recordings so you can learn on your schedule.
Here are some examples of my live crash courses:


